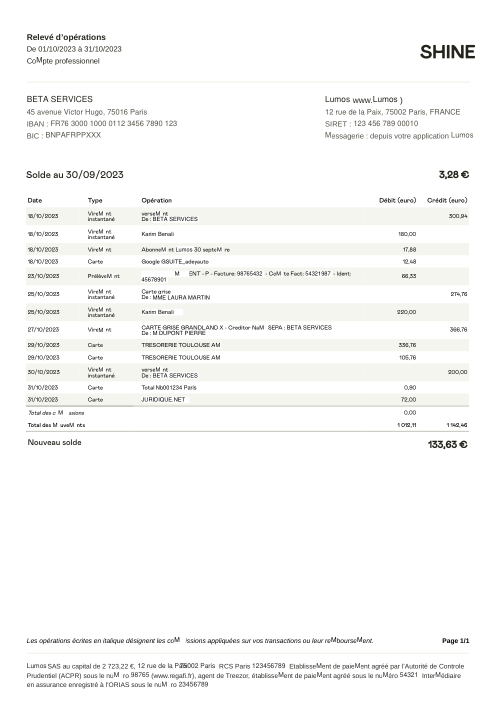
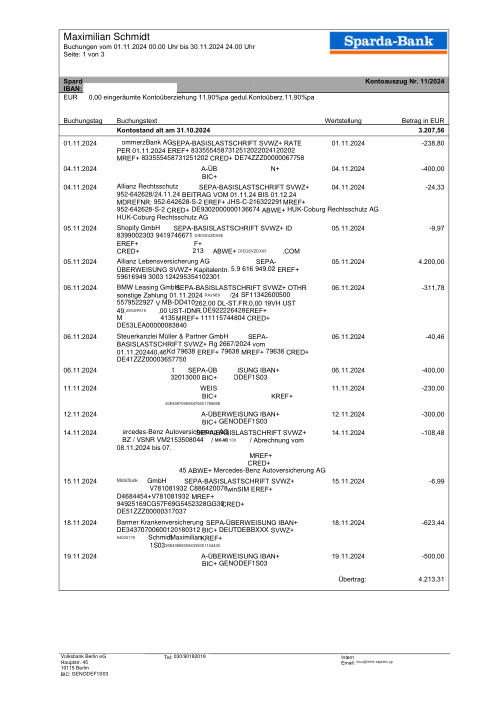
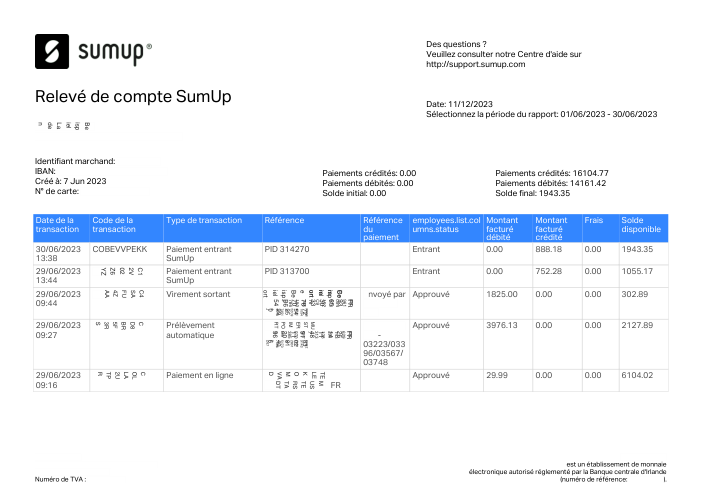
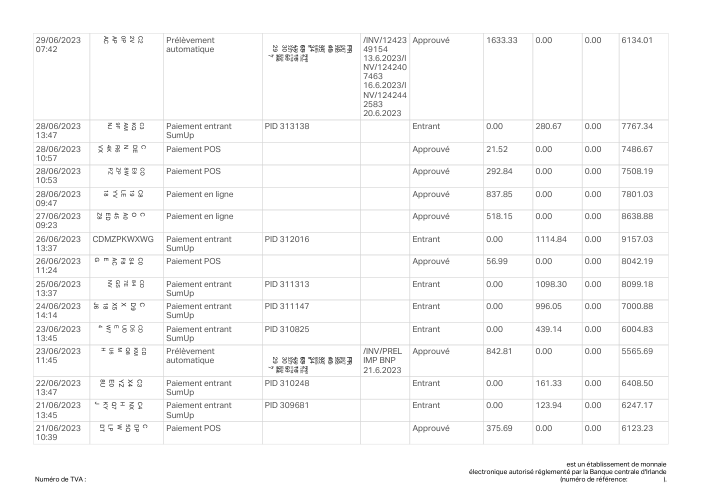
At holofin, bank-statement extraction is one of our core jobs, and we run it in production. Lenders, accountants and finance teams hand us statements from hundreds of different banks and expect every transaction back, exactly, with nothing invented and nothing dropped.
Extraction sits at the very front of that pipeline, so its mistakes never stay put. One missing or fabricated row doesn't just shave a point off an accuracy score. It becomes a balance that won't reconcile, an affordability decision built on a number that was never on the page, a ledger no one downstream can trust. A bank statement is boolean: it is either entirely correct, or it is a liability.
So we wanted to know how reliably today's best models actually do this, not on a hand-picked demo but on real statements, graded the way a finance team grades them, where the only thing that counts is whether the whole statement holds. We built a benchmark to find out.
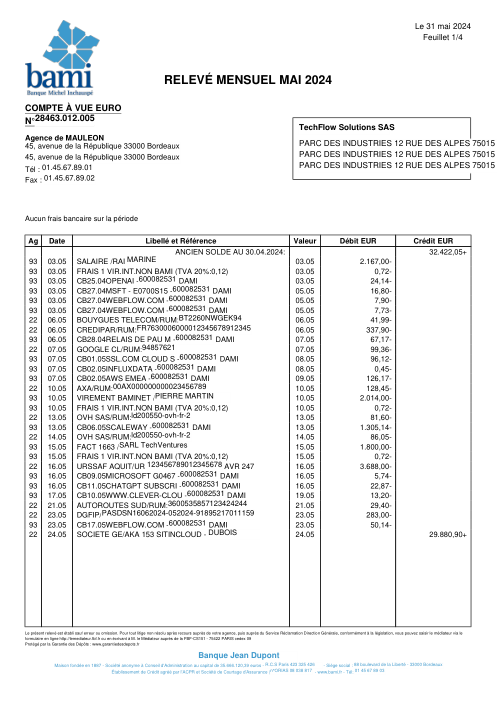
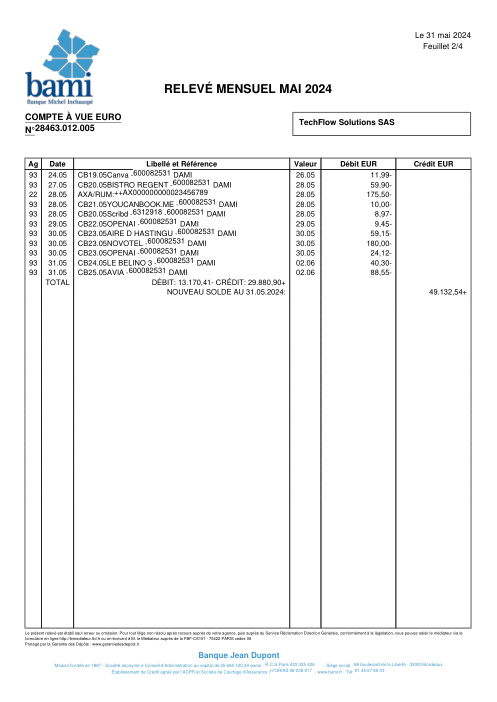
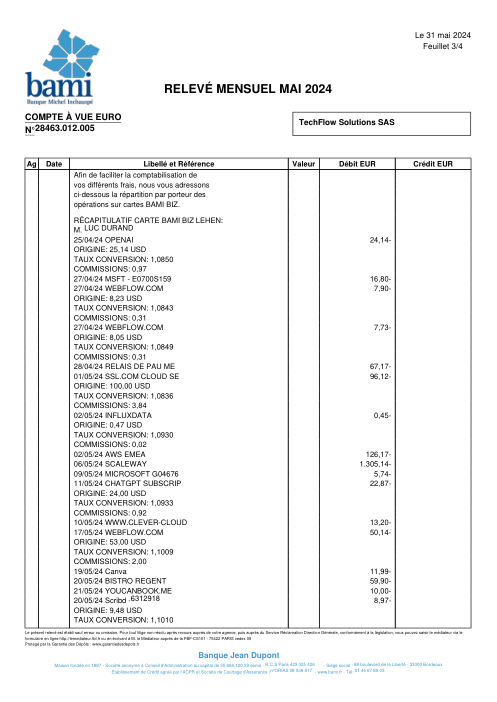
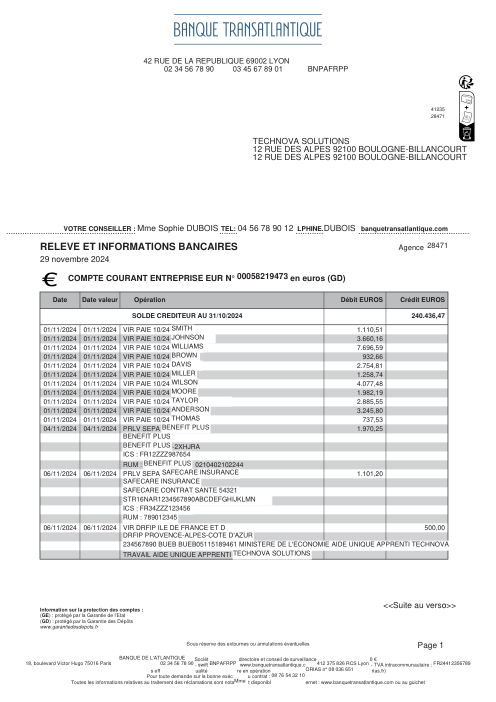
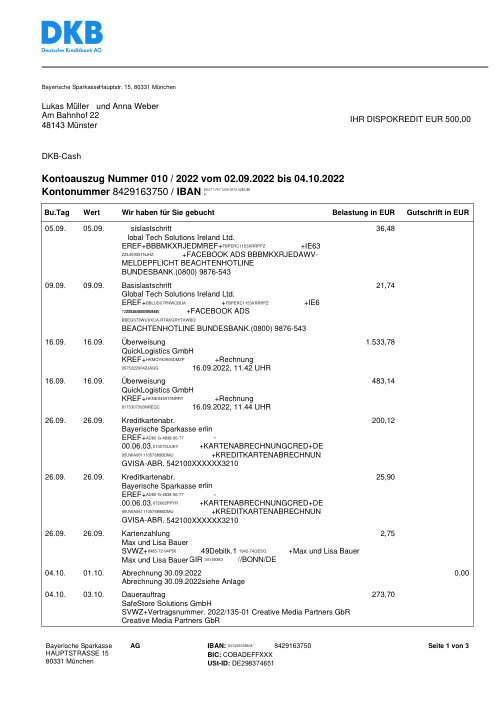
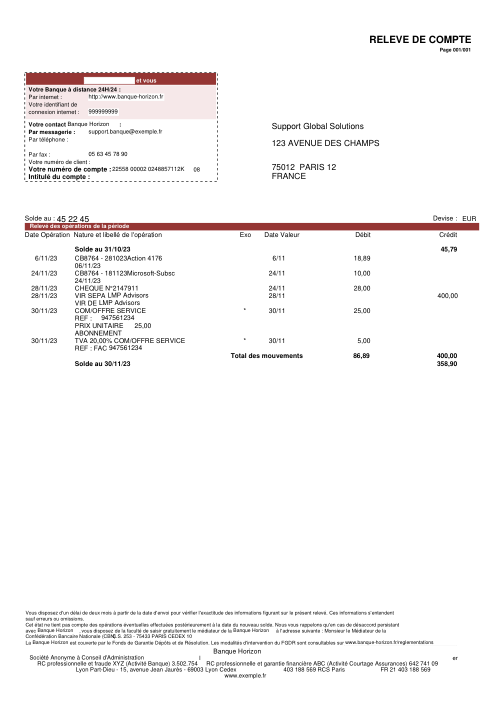
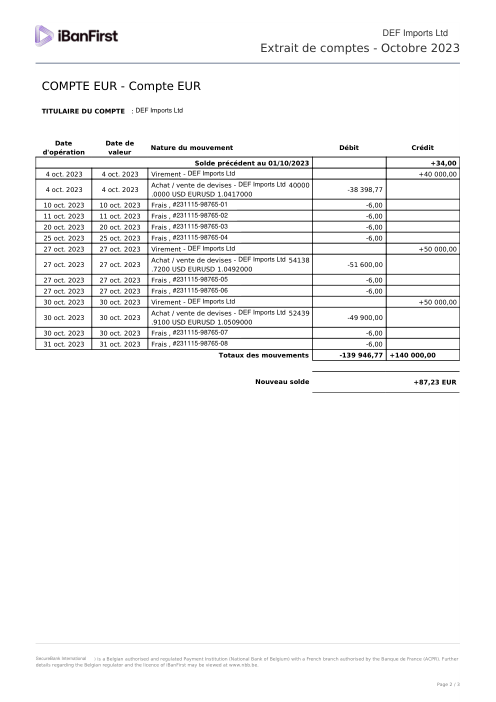
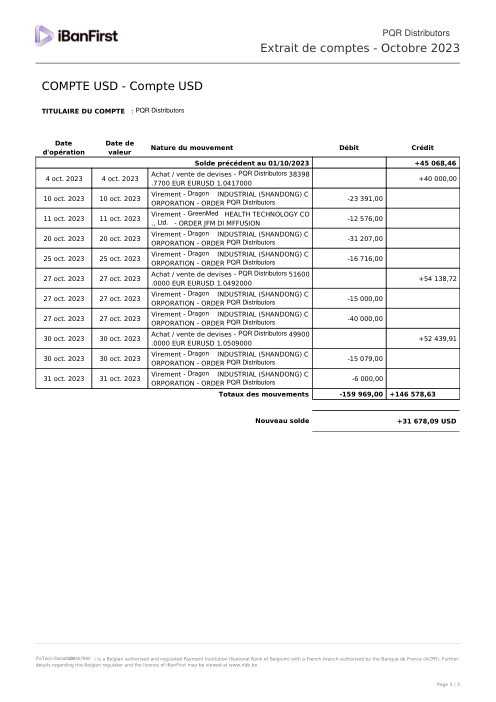
The dataset47 real statements, one per bank
Every statement is real, then anonymized so layout, tables and totals survive but the names and numbers are synthetic: French majors, German banks, neobanks and EMIs, each with its own idea of what a transaction table should look like. The gold labels were hand-verified against the source PDFs.
Every statement is real, then anonymized so layout, tables and totals survive but names and numbers are synthetic. Click any page to zoom; switch to By bank to filter.


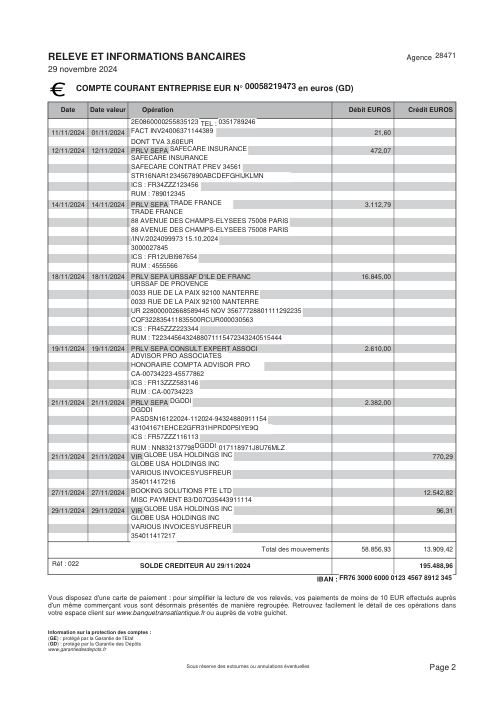







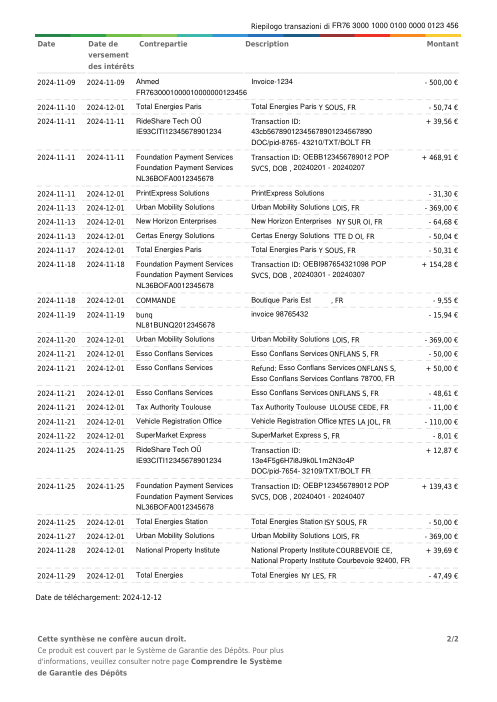









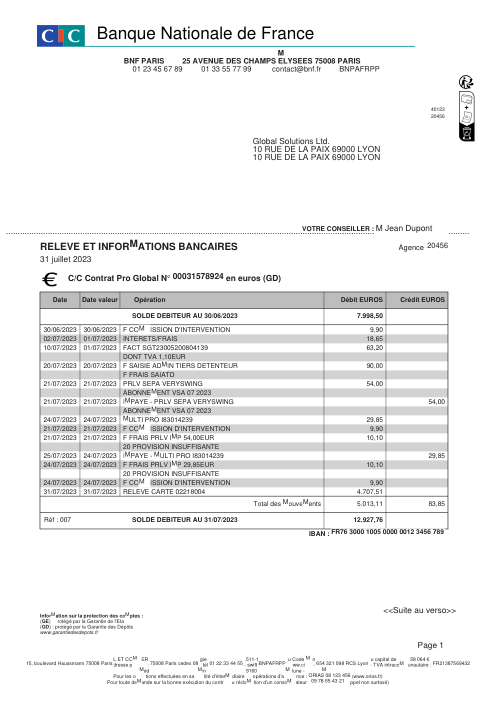
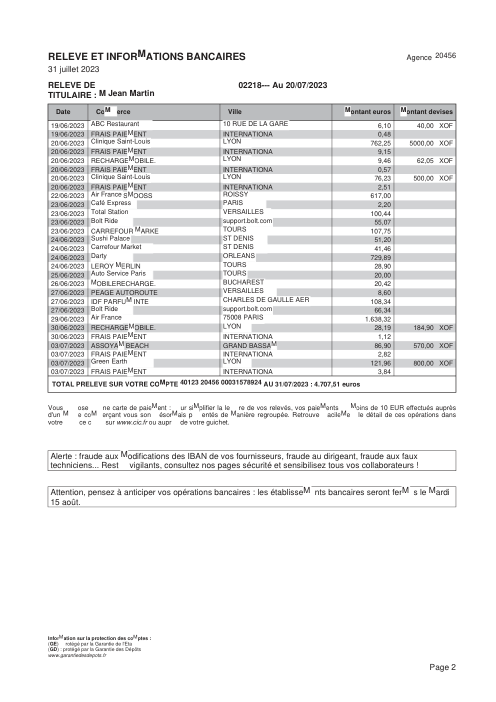





















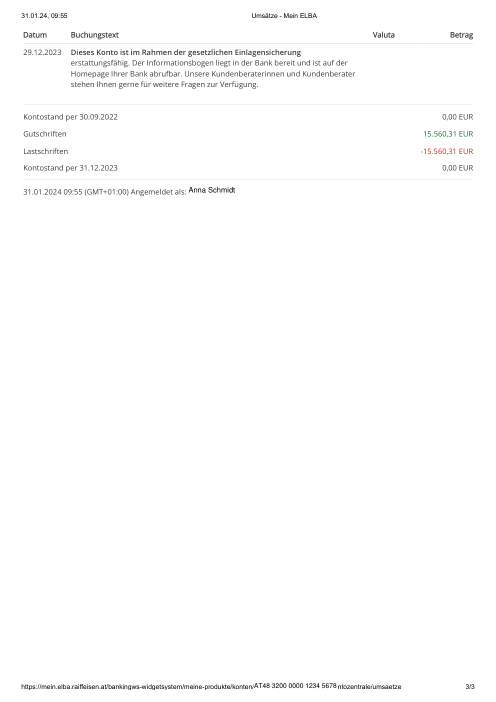


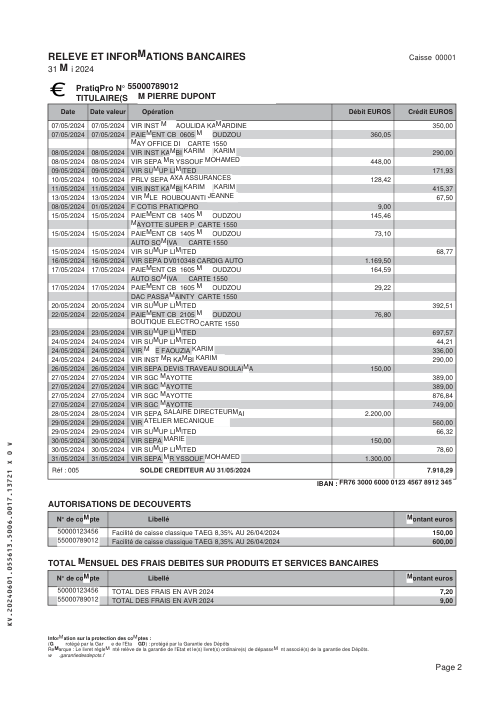


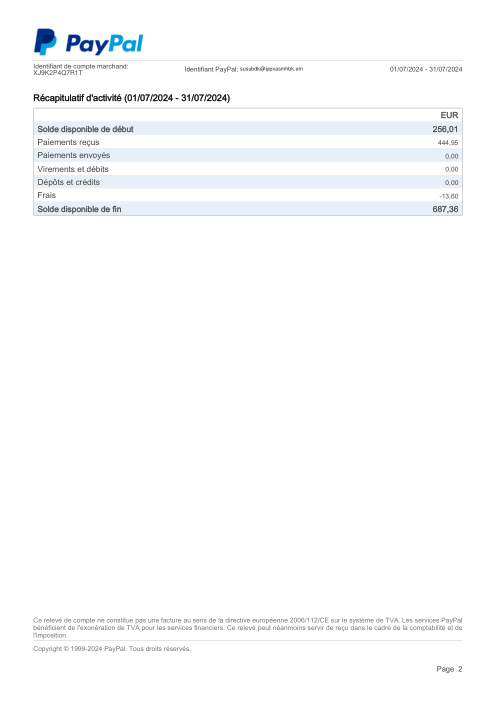
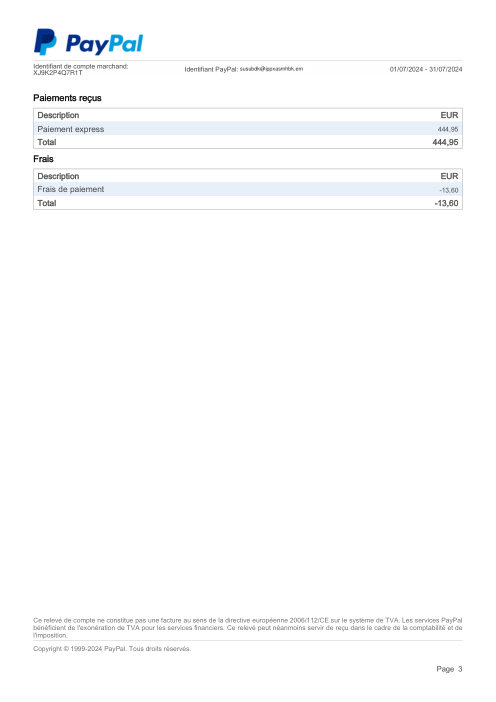
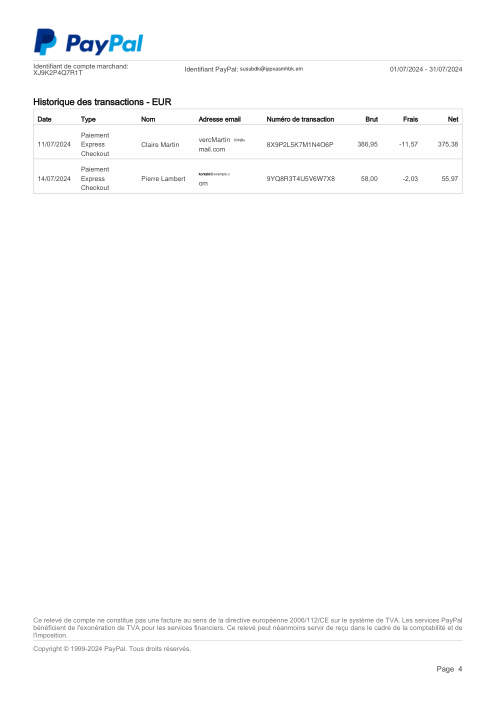


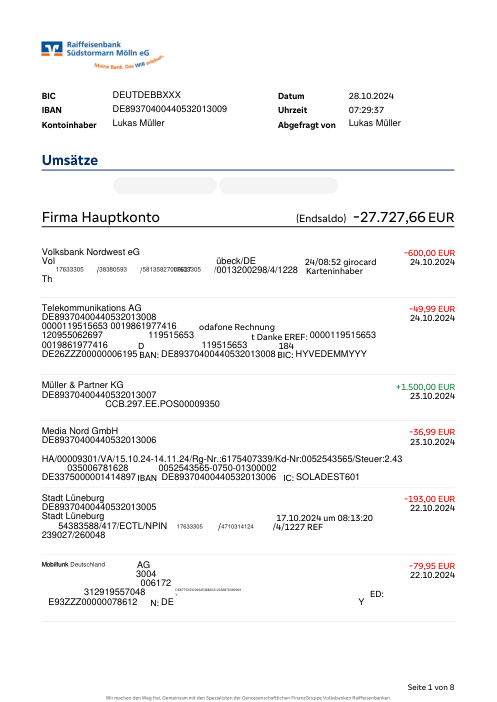


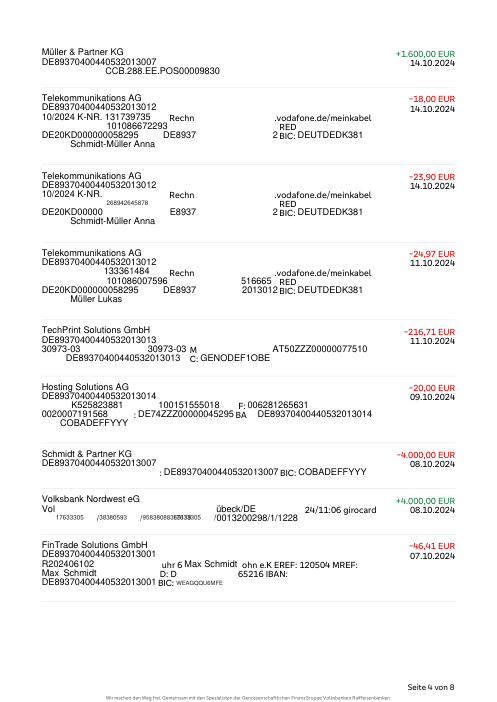


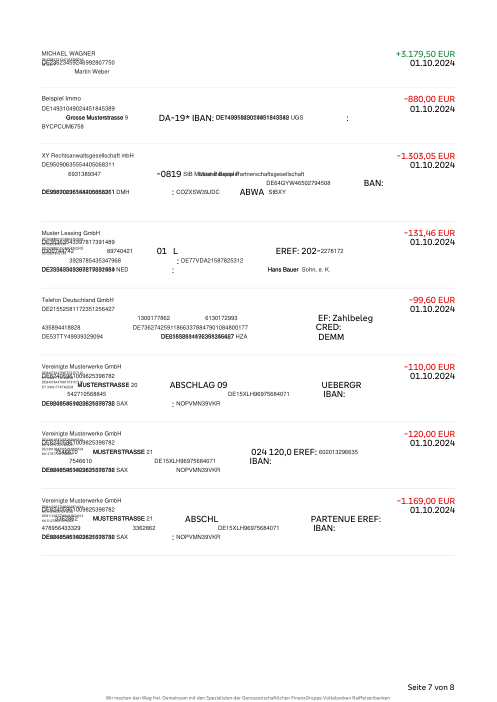







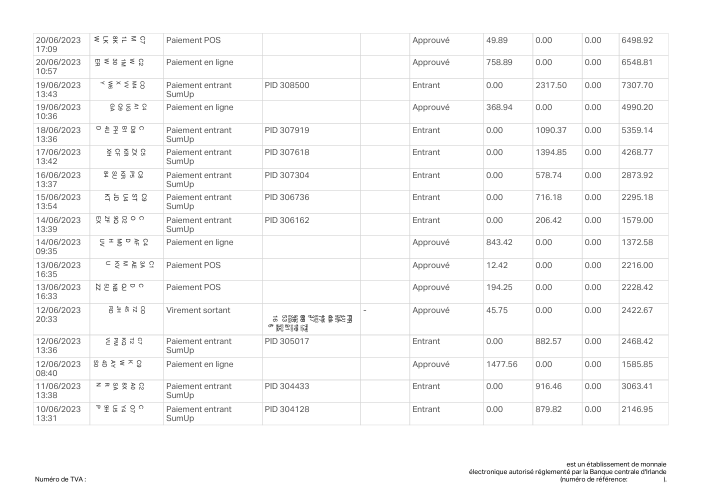
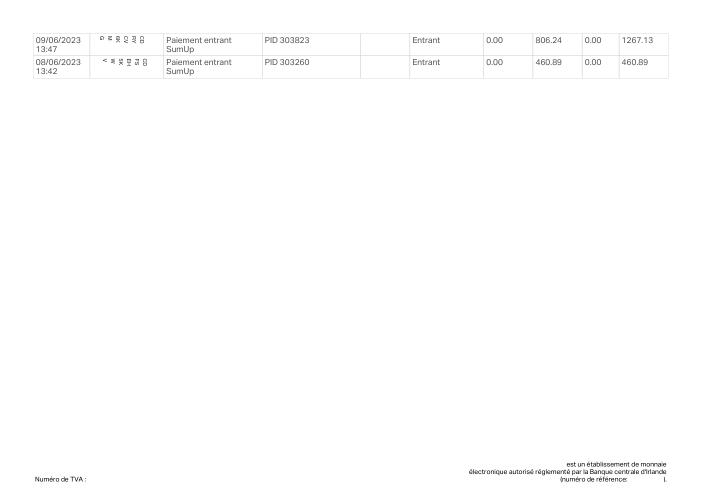




Per-row accuracy is a vanity metric
The number that matters to a customer is not "what fraction of rows are right" but "is this statement right." Those are not the same metric. A statement is correct only if every row is, so one missed or invented row fails the whole document.
- Per-statement, not per-row. holofin extracts 98% of statements with zero errors; the best frontier model manages 80%. Across 44 documents holofin produced one errored row; the frontier models produced 70–115 each.
- The gap is fabrication, not reading. Every system reads the page well (recall 0.88–1.00). The misses are rows the model returns that aren't on the page: about 8–10% of the rows a frontier model hands back don't match any transaction on the statement. We traced every one by hand — 68–93% of them (by model) have no counterpart on the page at all, genuine fabrication; the rest are a real row read with a wrong amount or date. holofin: one such row in 44 statements.
- The risk is the tail, not a steady tax. The errors aren't spread evenly — most statements come back clean across every model, but a handful of layouts fail hard. One invented row fails the whole statement, and nothing tells you in advance which document it will be.
- A bigger window is not the fix. Feeding more pages per call is a wash; per-page is reliable because it bounds fabrication.
What we found
Four reads of the same benchmark. The first places every system on completeness (did it find the rows?) against accuracy (are the rows it returned real?). The rest follow the arithmetic from there.
Every system finds the rows (completeness, x). They differ on how many of the rows they return actually exist (accuracy, y). holofin sits in the top-right corner; frontier models drop down the accuracy axis as they fabricate. Frontier shown per-page.
A statement is correct only if every row is. Share of statements extracted with zero errors (no dropped rows, no fabricated rows) against the hand-verified gold. The sub-label is total errored rows across all 44 documents: holofin made one; the frontier models made dozens.
Of every row a model hands back, the share whose (date, amount) is not on the page. We traced each one by hand: roughly 68–93% (by model) have no counterpart on the page at all — genuine fabrication; the rest are a real transaction read with a wrong amount or date. A fabricated row reconciles to a wrong balance and looks plausible: the silent failure. Frontier shown at their best (per-page) setting.
holofin runs one page at a time and tops every axis. For the frontier models, feeding more pages per call is a wash: recall slips a little, precision ticks up a little, two-page is often the sweet spot. The gap that matters is the one to the green bar.
The errors aren't a steady tax — they pile up on a handful of layouts (bami,
crédit industriel, raiffeisenbank, paypal…) while most statements come back clean across
every model. That's the real risk: not a predictable 10%, but a few layouts that fail hard,
with no way to know in advance which document you're holding — and one bad row fails the whole
statement. Raw count of errored rows (dropped + fabricated, vs gold) per statement, per-page
setting; one statement per bank, so rare layouts are over-represented. holofin's column is
empty. · = clean; numbers = errors on that document.
The quiet destruction of the invented row
It isn't a failure to read the ink on the page. If a transaction is visibly printed, every model finds it. The problem is what they find when the transaction isn't there. There is a massive operational difference between a dropped row and a fabricated one. A dropped row is annoying: the balance fails to reconcile and an operator spots the gap. A fabricated row is a silent killer. The model scrapes a running balance, a subtotal or a stray date and formats it as a valid transaction. It looks perfectly plausible doing it. It just slowly, invisibly poisons the arithmetic.
What "invented" means here — and what it doesn't
We match each returned row to the page on its (date, signed amount) at cent
precision. A returned row that matches nothing counts against the model. That bucket isn't all the
same thing, so we traced every non-matching row by hand: 68–93% of them
(depending on the model) have no counterpart on the page at all — a running balance, a subtotal or
a stray figure dressed up as a transaction. The remainder are a real transaction
read with a mangled amount or date. Both make the statement wrong, but they are different failures —
and the majority is genuine invention, not an OCR slip. (One caveat: a misread is only
distinguishable from a fabrication when a sibling row survives to pair it with, so this split is a
lower bound on true fabrication.)
The gold is human, not a model
We did not let a model grade other models. The ground truth was built by hand: on every document where the systems disagreed, a person opened the source PDF and checked the transactions line by line. The benchmark scores against what is actually printed on the page, verified by a human, not against another model's opinion of it.
MethodologyHow the benchmark is wired
Frontier candidates receive page images with a generic extraction prompt at three context sizes. holofin is the real production pipeline (classify → OCR → per-page extract), driven over HTTP. Every metric is doc-macro: computed per document, then averaged.
44 statements, one per distinct bank, picked for layout diversity — not weighted by how often each bank shows up in real traffic. That deliberately over-represents rare and awkward layouts (a tiny Basque mutual, an eight-page German Raiffeisen co-op), which is exactly where the frontier models break. So read this as a worst-case probe of reliability, not a forecast of average production accuracy: a model clean on the common banks here can still be sunk by the next odd layout it meets. And holofin's single errored row across 44 docs is one encouraging data point, not a guaranteed rate.
The obvious production check is whether a statement's math ties out: opening balance + Σ transactions = closing balance. We measured it, and it is necessary but not sufficient as a truth metric. GPT-5.5's statements reconcile 42/45 of the time, yet it still fabricates ~8% of rows against the actual page; a fabricated row offset by another error still ties out, and a model that omits balances entirely (Gemini left them blank on 12 documents) can't be checked at all. A statement can pass the math and still be wrong. So we score every transaction against gold that was hand-verified against the source PDF.
You don't need a larger window. You need a harness.
You don't solve extraction by passing an entire PDF to an endpoint and asking a model to be careful. At holofin that's the job description. We build the cage the intelligence runs inside:
- Structure before semantics. Deterministic OCR and geometry build the page context first. Prompts capture meaning well and visual structure poorly.
- Bound the problem. We process strictly per-page, never asking a model to hold an entire ledger in working memory.
- Constraints > vibes. Strict accounting rules decide what counts as a transaction before a result is ever finalized.
Once you've written enough scaffolding to be safe (the OCR redundancy, the bounding geometry, the strict parsers, the reconciliations), the model is no longer the hero. It's the specialist you page in for disputes and edge cases. The job isn't to eliminate the boring bits; it's to build boring things so the magic has something sturdy to stand on.
Related Articles

Your Table Extractor Passed. The Numbers Didn't.
An auditor opens your extraction output for a balance sheet. The model reports 99.2% cell accuracy. Impressive. Then she totals the asset column by hand, the way auditors do, and it comes to a number that is off by one row. Assets no longer equal liabilities plus equity. The statement does not close.

Document Fraud Detection: What a PDF Can't Hide
We used to think document fraud was a visual problem. Wrong fonts. Misaligned columns. A logo that felt slightly off. We built checks around what humans see, because what humans see is all we had.

When Documents Fight Back
Page 1: Account summary, two columns. Page 15: Same account, three columns, different header names. Page 47: A scan with a coffee stain. Page 89: The totals page, which references transactions you extracted 70 pages ago.